
Si tu as déjà affirmé : « Nous faisons du GitOps » parce qu'un pipeline Jenkins, GitLab CI ou GitHub Actions exécute un kubectl apply après un merge sur main, tu n'es pas seul. Après tout, Git est au centre du processus, l'infrastructure est définie sous forme de code et les déploiements sont automatisés.
Sur le papier, cela ressemble effectivement à du GitOps. La confusion est partout : dès qu'un workflow touche un dépôt Git, on pourrait l'étiqueter GitOps. Mais Git n'est pas ce qui définit ce qu'on appelle GitOps. Ce qui le définit, c'est avant tout le sens du flux.

Figure 1 — CI/CD classique pousse vers l'infrastructure ; GitOps tire l'état désiré depuis Git et l'applique de façon déclarative et continue.
Le vrai clivage : pull vs push
Mets côte à côte deux architectures de déploiement.
Le modèle push (Jenkins, GitHub Actions, GitLab CI classique). Un événement — un commit, une PR mergée — déclenche un pipeline. Ce pipeline build, teste, puis pousse l'état désiré vers le cluster depuis l'extérieur. Le CI a les credentials du cluster, ouvre une connexion, applique les manifestes. Le cluster est passif ; il subit.
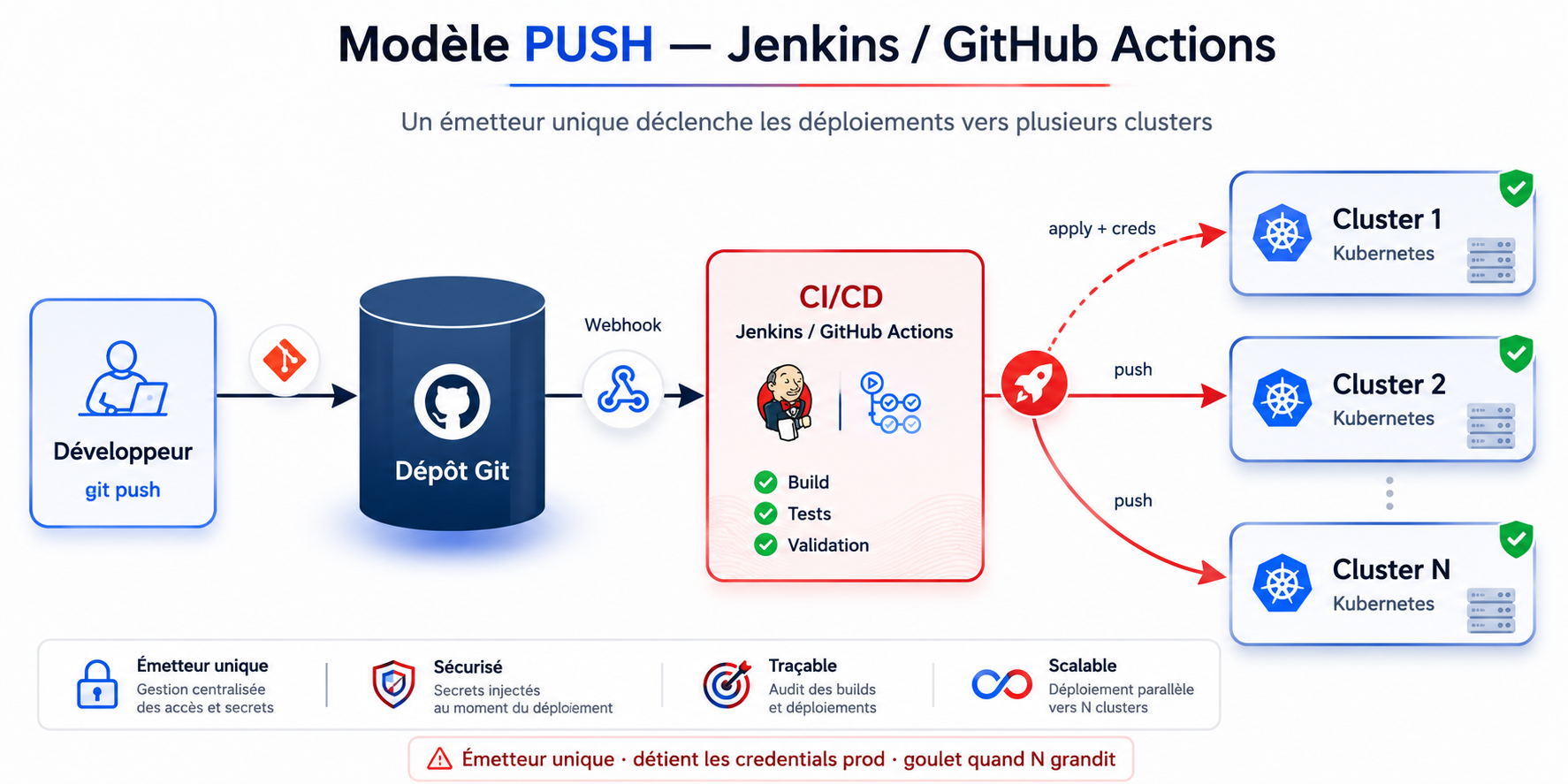
Figure 2 — Modèle PUSH (Jenkins / GitHub Actions) : un émetteur central pousse l'état désiré vers chaque cluster.
Le modèle pull (GitOps : Argo CD, Flux). Un agent vit à l'intérieur du cluster. Il surveille en continu un dépôt Git qui décrit l'état désiré, compare avec l'état réel, et réconcilie. Le cluster tire sa propre vérité et se corrige tout seul.
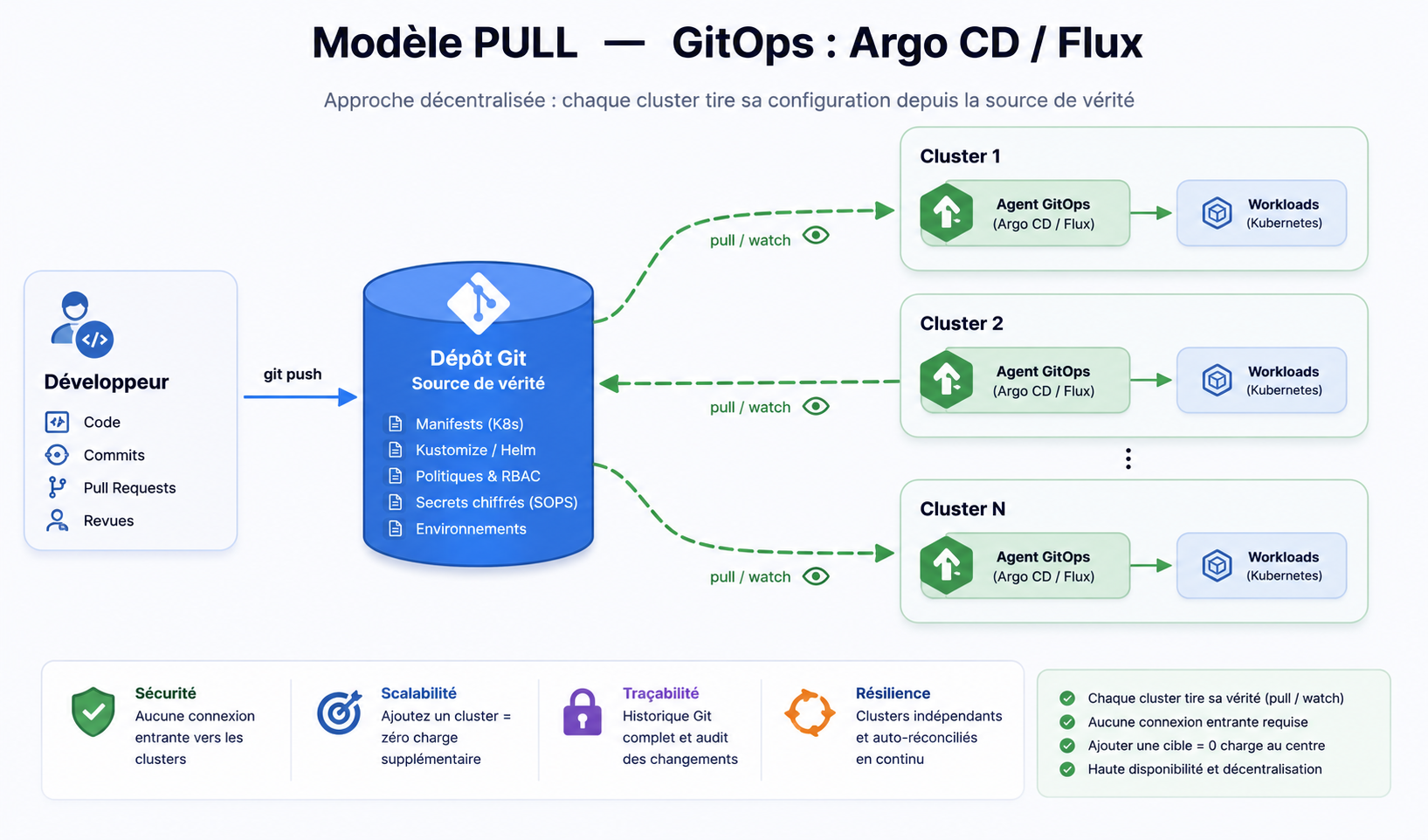
Figure 3 — Modèle PULL (GitOps : Argo CD / Flux) : chaque cluster tire sa vérité depuis le dépôt, sans connexion entrante.
Les deux utilisent Git. Un seul est GitOps. La différence n'est pas l'outil, c'est qui prend l'initiative de la convergence.
Pourquoi cette distinction change tout
Ce n'est pas une querelle de vocabulaire. Les deux modèles ont des propriétés opérationnelles radicalement différentes.
Le drift. Dans le modèle push, l'état réel du cluster n'est garanti qu'au moment du déploiement. Quelqu'un fait un kubectl edit à 3h du matin ? Le dérive (drift) persiste jusqu'au prochain pipeline. Dans le modèle pull, l'agent détecte l'écart et le corrige en continu : Git est la seule source de vérité, et le cluster y est constamment réaligné.
La sécurité. Le push exige que ton CI détienne les credentials de production — une surface d'attaque qui sort du périmètre du cluster. Le pull inverse la relation : rien de l'extérieur n'a besoin d'accès au cluster, c'est lui qui va chercher l'information. Pour des environnements sensibles, ce détail n'en est pas un.
Le point qui fait vraiment basculer : la scalabilité
Voilà où le débat cesse d'être théorique.
Si tu gères une poignée d'applications, le push suffit largement. Honnêtement, monter Argo CD pour trois services, c'est se compliquer la vie. Un pipeline qui déploie, ça marche, c'est lisible, c'est maintenable.
Mais le modèle push scale mal, et c'est mathématique. Chaque cible de déploiement est une connexion sortante que ton orchestrateur central doit initier, authentifier et maintenir. Multiplie par des dizaines de clusters, des centaines de workloads, et ton CI devient un goulot d'étranglement et un point de défaillance unique. Tu pousses vers N cibles depuis un seul endroit.
Le pull renverse la charge. Chaque cluster est responsable de sa propre convergence. Ajouter une cible n'ajoute aucune charge au centre : le nouvel agent va lui-même chercher son état dans Git. Tu passes d'une topologie « un émetteur, N récepteurs » à « N agents autonomes, une source de vérité ».
C'est la différence entre arroser mille plantes à la main et installer un goutte-à-goutte que chaque plante régule elle-même.
Là où ça devient vraiment intéressant : l'edge, l'IoT, les véhicules
Pousse le raisonnement à l'extrême. Imagine que tes « clusters » ne sont pas dans un datacenter mais dans des milliers de véhicules, de passerelles industrielles, de bornes connectées.
Le modèle push est ici tout simplement impossible. Tu ne peux pas ouvrir une connexion sortante vers un véhicule qui passe d'un réseau mobile à un tunnel sans couverture, ou vers une flotte de capteurs derrière des NAT et des firewalls que tu ne contrôles pas. L'adresse change, la connectivité est intermittente, et ils se comptent par milliers.
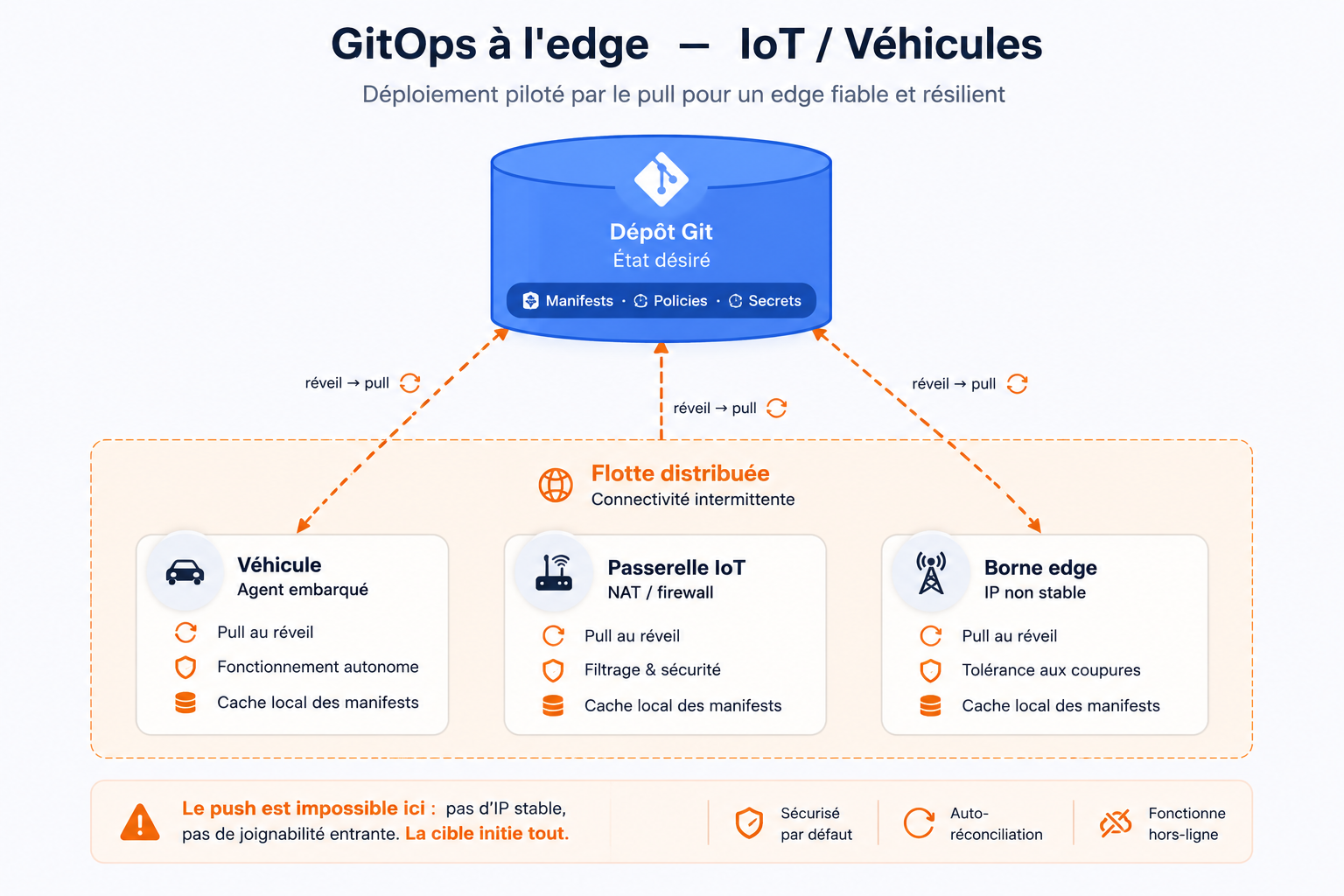
Figure 4 — GitOps à l'edge (IoT / véhicules) : chaque cible se réveille et tire son état désiré ; le push y est impossible.
Le modèle pull est fait pour ça. L'agent embarqué se réveille quand il a du réseau, tire son état désiré, se met à jour, et se rendort. Pas besoin de joignabilité entrante. Pas besoin d'IP stable. La connectivité intermittente devient un non-problème : la réconciliation reprend simplement à la prochaine fenêtre. C'est, fondamentalement, le bon modèle mental pour le déploiement distribué à l'échelle de l'edge.
Solutions et outils compatibles avec l'approche GitOps
Lorsque l'on parle de GitOps, les noms d'Argo CD et Flux viennent immédiatement à l'esprit. Pourtant, le principe est plus ancien que Kubernetes et peut être appliqué à de nombreux outils d'automatisation et de gestion de configuration.
GitOps natif Kubernetes
Ces solutions implémentent directement le modèle GitOps :
- surveillance continue du dépôt Git ;
- réconciliation automatique ;
- détection de dérive ;
- retour à l'état désiré.
GitOps pour serveurs et infrastructures traditionnelles
Bien avant Kubernetes, certains outils appliquaient déjà des concepts très proches du GitOps moderne :
Particulièrement intéressant :
Ansible Pull inverse complètement le modèle traditionnel Ansible.
Au lieu d'un serveur central qui pousse les changements vers les machines, chaque nœud récupère lui-même sa configuration depuis Git, reproduisant presque exactement le comportement d'un agent GitOps moderne.
GitOps et systèmes déclaratifs
Certains systèmes vont encore plus loin en rendant l'ensemble du système d'exploitation déclaratif.
Avec NixOS :
- l'état complet de la machine est décrit dans Git ;
- les déploiements sont reproductibles ;
- les rollbacks sont natifs ;
- l'infrastructure converge vers l'état déclaré.
Beaucoup considèrent d'ailleurs NixOS comme l'une des implémentations les plus pures de la philosophie GitOps.
GitOps pour l'Edge et l'IoT
Le modèle pull est particulièrement adapté aux environnements distribués :
- véhicules connectés ;
- objets IoT ;
- passerelles industrielles ;
- sites distants derrière du NAT.
Exemples :
Dans ces environnements, le push est souvent impossible à cause de l'absence d'IP publique ou d'une connectivité intermittente. Le modèle GitOps devient alors non seulement pratique, mais parfois indispensable.
Une définition plus large du GitOps
Si l'on retire Kubernetes de l'équation, on peut résumer GitOps ainsi :
Une cible autonome observe une source de vérité déclarative, récupère les changements lorsqu'elle est joignable, puis se réconcilie automatiquement vers l'état désiré.
Sous cet angle, Argo CD, Flux, Puppet, CFEngine, Ansible Pull ou encore NixOS ne sont pas des technologies concurrentes : ce sont différentes implémentations d'une même idée. Le véritable critère n'est pas l'outil utilisé, mais la présence d'une source de vérité déclarative et d'un flux de réconciliation initié par la cible.
Ce qu'il faut retenir
GitOps n'est pas « utiliser Git dans ton CI/CD ». C'est un modèle pull, déclaratif, à réconciliation continue, où l'agent vit dans la cible et va chercher sa vérité.
Push contre pull, sur les axes qui comptent :
- Drift — Push : corrigé seulement au prochain déploiement. Pull : détecté et réaligné en continu.
- Sécurité — Push : le CI détient les credentials prod, surface d'attaque externe. Pull : aucune connexion entrante, le cluster va chercher sa vérité.
- Scalabilité — Push : un émetteur, N cibles, goulot d'étranglement central. Pull : N agents autonomes, zéro charge ajoutée au centre.
- Edge / IoT — Push : impossible sans IP stable ni joignabilité entrante. Pull : conçu pour la connectivité intermittente.
Le push n'est pas inférieur — il est différent, et parfait pour les petits périmètres. Mais dès que tu multiplies les workloads, les clusters ou que tu attaques l'edge, le pull n'est plus une préférence : c'est une nécessité architecturale.
La prochaine fois que quelqu'un dit « on fait du GitOps », pose la seule question qui tranche : qui initie le déploiement — ton pipeline, ou le cluster lui-même ?
Tu fais du push ou du pull ? Et où places-tu la frontière dans ta propre infra ? Dis-le en commentaire.